Tuning Engines
Tuning Engines unifies, secures, and optimizes every AI interaction through one governed API, continuously improving cost, quality, and control.
Visit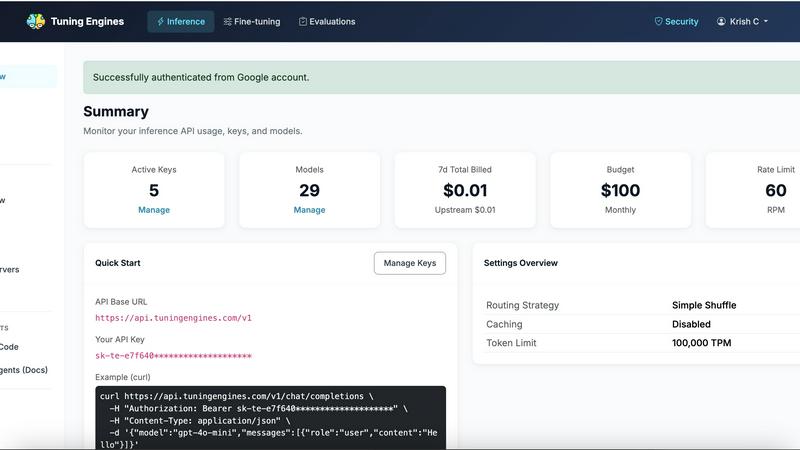
About Tuning Engines
Tuning Engines is a unified AI control and governance layer, built by CerebrixOS, that acts as a universal intelligence runtime for teams building production-grade AI systems. It consolidates the entire AI lifecycle into a single, governed platform, enabling organizations to move beyond isolated experiments into a secure, observable, and cost-aware operating layer. The platform brings together inference, model routing, fine-tuning, evaluations, agent management, and policy enforcement under one roof. For developers, it provides OpenAI-compatible APIs and Anthropic-compatible routes, allowing them to connect tools like Claude Code, Cursor, and VS Code without rewriting their stack. For admins, it offers role-based access, per-key budgets, rate limits, and full auditability. The core value proposition is that organizations can train, evaluate, route, and govern models at scale, while using them with agents and tools. Tuning Engines is built for teams building code assistants, conversational AI, agentic systems, and enterprise RAG pipelines. It is backed by Google Cloud for Startups, NVIDIA Inception, and AWS Activate, and it operates on a different pricing model where infrastructure costs are passed through at-cost with zero markup, meaning users only pay for support and platform upkeep.
Features of Tuning Engines
Unified Inference through One API
Tuning Engines provides a single, OpenAI-compatible endpoint that gives access to over 100 models, including open-weight models like Llama 3.3, DeepSeek V3, and Qwen 2.5, as well as commercial frontier models and your own custom tuned models. Developers can keep their existing SDK and simply swap one base URL to call any model, with centralized policy, full auditability, and token controls applied to every request. This eliminates the need to manage multiple API keys or learn new client libraries.
Model Tuning and Lifecycle Management
The platform enables teams to adapt open models to their specific data, language, and production goals. Users can run supervised fine-tuning and LoRA adapters directly on the platform without managing GPU infrastructure. The model lifecycle is built around three phases: Build (hit one endpoint for any model), Tune (adapt models with your data), and Scale (host your own tuned variants). This cyclical process allows for continuous improvement as models evolve with business requirements.
Centralized Policy and Governance
Admins get granular control over every AI interaction through role-based access, per-key budgets, rate limits, routing profiles, and fallback rules. The platform includes policy-as-code with AGT YAML policies, guardrails, and credential sources. Every request is traceable with full auditability, usage traces, and billing controls. This ensures that organizations can maintain security and compliance while scaling their AI operations across multiple teams and tenants.
Evaluations and Quality Measurement
Tuning Engines includes built-in evaluation capabilities that allow teams to measure quality, compare model variants, and ship with evidence. The platform supports evaluation gates so that quality moves in tandem with business objectives. This feature is essential for teams that need to validate model performance before deploying to production, ensuring that every iteration of a model is tested against defined metrics.
Use Cases of Tuning Engines
Code Assistance and IDE Copilots
Development teams can build and deploy AI-powered code assistants that integrate directly with IDEs like VS Code, Cursor, and Windsurf. Using the unified API, developers can route requests to the best model for code generation, refactoring, or debugging. The platform supports tools like Claude Code, OpenCode, Aider, and Continue.dev, enabling a single governed platform for all coding-agent workflows. This ensures that code assistance is both powerful and compliant with organizational policies.
Conversational AI and Customer Support
Organizations can deploy customer support bots, internal helpdesks, and multilingual chat systems using the platform's unified inference and model routing capabilities. By leveraging fallback policies and guardrails, teams ensure that conversations remain safe and on-brand. The platform's token economics and cost ceilings keep spend predictable, while usage analytics provide insights into customer interactions. This allows for continuous improvement of conversational flows based on real-world data.
Agentic Systems and Multi-Step Reasoning
Teams building complex agentic systems that require multi-step reasoning, planning, and tool usage can leverage Tuning Engines' support for agents, MCP servers, and reusable skills. The platform provides resource catalogs for models, agents, tools, and skills, enabling agents to dynamically select the best model for each step. With centralized policy and runtime traces, every action taken by an agent is auditable, making it suitable for mission-critical workflows.
Enterprise RAG and Knowledge Retrieval
Enterprises can build secure, scalable retrieval-augmented generation (RAG) systems over private knowledge bases and documents. The platform supports embeddings models from the BGE and E5 families, and it integrates with enterprise data sources through credential management and tenant isolation. By using one API for both embedding and generation, teams can create personalized recommendation systems and enterprise assistants that are both accurate and governed by organizational policies.
Frequently Asked Questions
What is Tuning Engines and who is it for?
Tuning Engines is a unified AI control and governance layer built by CerebrixOS. It is designed for teams building production intelligence across models, agents, tools, and fine-tuned systems. It is ideal for developers who want a single API to access any model, and for admins who need centralized policy control, auditability, and cost management. The platform serves use cases from rapid prototyping to mission-critical workflows.
How does the pricing model work?
Tuning Engines operates on a pass-through pricing model for infrastructure costs. The platform passes GPU compute and other infrastructure costs at-cost with zero markup. Users only pay for support and platform upkeep. This means organizations do not pay extra for the underlying hardware, making it a cost-effective solution for scaling AI operations. Specific plan pricing details are available by contacting the team.
What models are available through the unified API?
The platform provides access to over 100 models through one OpenAI-compatible endpoint. This includes open-weight models like Llama 3.3 70B, DeepSeek V3, Qwen 2.5 72B, Mistral Small 3, and Gemma 2 27B. It also supports reasoning models like DeepSeek R1, vision models like Llama 3.2 Vision, audio models like Whisper Large v3, and embedding models from the BGE and E5 families. Additionally, users can add their own fine-tuned models to the same endpoint.
How does Tuning Engines ensure security and governance?
The platform provides role-based access control, per-key budgets, rate limits, and routing profiles. It supports policy-as-code with AGT YAML policies, guardrails, and credential sources. Every request is fully traceable with runtime traces and usage analytics. The platform also offers tenant isolation and team management, ensuring that different departments or clients can operate securely within the same infrastructure.
Pricing of Tuning Engines
Tuning Engines operates on a unique pricing model where infrastructure costs are passed through at-cost with zero markup. This means users pay only for the underlying GPU compute and resources without any additional margin from the platform. The platform charges separately for support and platform upkeep. Specific pricing plans, tiers, and detailed cost information are not publicly listed and are available upon request by contacting the sales team or starting a trial through the website.
Similar to Tuning Engines
Distro is an AI Distribution Operator that helps B2B teams publish content, find buyer conversations, engage prospects, and turn social intent into pi
Polymarket Trading Bot For Crypto
Skygen AI helps you continuously improve how you work by automating tasks, building AI agents, and refining workflows for better results.
HyperLake provides sovereign AI infrastructure with $0 compute markup, enabling autonomous agents to explore and innovate without limits.
Record once to train AI agents that clear tasks off your plate, then iterate to improve their performance continuously.
YCaaS delivers comprehensive AI agents that seamlessly manage all roles and processes, driving efficiency and innovation in your organization.
xyOps continuously evolves your infrastructure automation with visual workflows, smart monitoring, and adaptive job scheduling.
Playwriter lets AI agents control your real Chrome browser with all your logins and extensions intact.