WebPageSnap - Professional Web Scraper API
WebPageSnap is a powerful API that effortlessly scrapes any webpage with smart caching and lightning-fast response.
Visit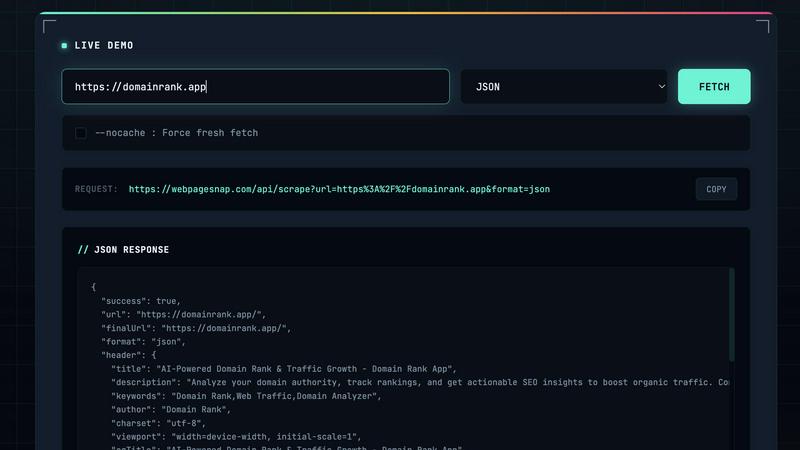
About WebPageSnap - Professional Web Scraper API
WebPageSnap is an enterprise-grade web scraping API service that transforms the intricate task of web content extraction into a straightforward and efficient API call. Designed specifically for developers and businesses, it provides reliable, fast, and structured access to web data. Leveraging the powerful Cloudflare Workers platform, WebPageSnap operates across a global network of over 200 edge locations, ensuring that users experience lightning-fast response times of 20-50 milliseconds for cached requests. This service is crafted for continuous improvement, utilizing an intelligent caching system that learns from traffic patterns to enhance performance and operational efficiency. Whether you are a solo developer constructing data-driven applications or a large enterprise looking to aggregate market intelligence, monitor competitors, or archive web content at scale, WebPageSnap stands out. Its core value proposition lies in its simplicity, speed, and intelligence, offering a "set-and-forget" scraping infrastructure that evolves over time, ensuring your data pipeline becomes more efficient with increasing usage.
Features of WebPageSnap - Professional Web Scraper API
Smart Cache
WebPageSnap features a sophisticated caching mechanism that employs key-value storage with a seven-day time-to-live (TTL). This results in an impressive cache hit rate of over 95 percent, allowing users to retrieve data faster while minimizing unnecessary server load.
Global Edge
With over 200 edge nodes strategically deployed around the world, WebPageSnap guarantees the closest response to users, significantly reducing latency. This global distribution ensures that users can access web content swiftly, enhancing overall application performance.
Multi Format
The API provides flexibility by returning data in multiple formats, including structured JSON and raw HTML. This capability allows developers to choose the output format that best suits their application's requirements, facilitating seamless integration.
Smart Redirect
WebPageSnap automatically follows JavaScript redirects to ensure that users receive the final page content. This feature simulates real browser behavior to handle complex web pages effectively, ensuring accurate data extraction even from JavaScript-heavy sites.
Use Cases of WebPageSnap - Professional Web Scraper API
Market Research
Businesses can utilize WebPageSnap to gather data from competitor websites, enabling them to analyze market trends, pricing strategies, and product offerings. This information helps in making informed business decisions and staying competitive.
Content Monitoring
WebPageSnap is ideal for monitoring changes on particular web pages, such as news sites or blogs. Companies can automate the process of tracking content updates, ensuring they are always aware of the latest information relevant to their industry.
Data Aggregation
Developers can leverage WebPageSnap to aggregate data from multiple sources into a centralized database. This is particularly useful for creating dashboards or analytics platforms that require real-time data from various websites.
SEO Analysis
Digital marketers can use WebPageSnap to extract metadata and analyze competitors' SEO strategies. By retrieving title tags, descriptions, and keywords, they can refine their own SEO efforts and improve search engine rankings.
Frequently Asked Questions
What is a web scraper API?
A web scraper API is a service designed to programmatically extract content from websites. WebPageSnap offers structured data extraction in both JSON and HTML formats, which simplifies the integration of web scraping into various applications.
How does this web scraper API handle JavaScript pages?
WebPageSnap effectively manages JavaScript pages by automatically detecting and following redirects. It simulates real browser behavior to ensure that users receive the final content of the page, even for sites that rely heavily on JavaScript.
Is the web scraper API free to use?
Yes, WebPageSnap provides a generous free tier that allows users to make 100,000 requests per day. This offers a substantial opportunity for developers and businesses to explore the capabilities of the API without immediate financial commitment.
What types of data can be extracted using WebPageSnap?
WebPageSnap can extract a wide range of data types, including metadata (like titles, descriptions, and keywords), as well as the full HTML content of a web page. This versatility makes it useful for various applications, from market analysis to content monitoring.
Explore more in this category:
Similar to WebPageSnap - Professional Web Scraper API
Monitoristic provides real-time website health tracking with instant alerts and customizable status pages for seamless uptime management.
Sorsa API delivers fast, reliable X/Twitter data at 50x lower cost with 20 requests per second and setup in 3 minutes.
Keplars simplifies transactional and marketing email delivery with fast setup, strong deliverability, and a unified editor that iterates with your.
TrafficClaw transforms your SEO and analytics data into actionable insights through AI conversations, empowering you to optimize and grow your.
Linkfinder AI instantly enriches your data with complete company details, continuously improving your workflow.
BlitzAPI empowers your growth team with instant access to clean B2B data through powerful, scalable APIs for seamless.
LLMWise offers a single API for seamless access to top AI models, optimizing costs with pay-per-use flexibility.
Anti TempMail offers an email intelligence API that accurately verifies addresses to enhance growth while minimizing.