Agenta vs Fallom
Side-by-side comparison to help you choose the right product.
Agenta is the open-source LLMOps platform that centralizes prompt management and evaluation for reliable AI apps.
Last updated: March 1, 2026
Fallom delivers real-time AI observability to enhance, debug, and optimize your LLM agents with unmatched transparency.
Last updated: February 28, 2026
Visual Comparison
Agenta
Fallom
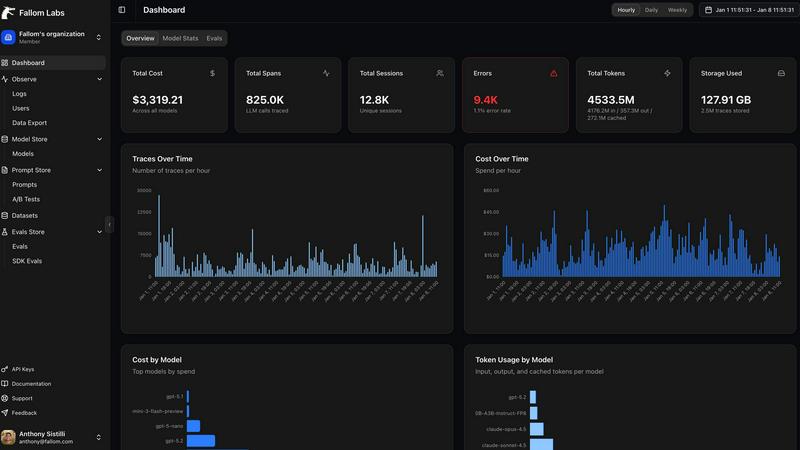
Feature Comparison
Agenta
Unified Playground & Experimentation
Agenta provides a centralized playground where teams can experiment with different prompts, parameters, and foundation models from various providers side-by-side in a single interface. This model-agnostic approach prevents vendor lock-in and allows for direct comparison. Every change is automatically versioned, creating a complete history of experiments so teams can track what worked, what didn't, and iterate efficiently based on real data, turning experimentation into a structured process.
Systematic Evaluation Framework
Replace guesswork with evidence using Agenta's comprehensive evaluation system. Teams can create automated test suites using LLM-as-a-judge, custom code, or built-in evaluators. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, to pinpoint failure points. The platform also integrates human evaluation, allowing domain experts to provide feedback directly within the workflow, closing the loop between automated and human judgment.
Production Observability & Debugging
Gain full visibility into your live AI applications with detailed tracing of every LLM request. When issues arise, teams can quickly drill down to find the exact source of errors. Traces can be annotated collaboratively and, with a single click, turned into permanent test cases for future experiments. This capability, combined with live performance monitoring and online evaluations, enables proactive detection of regressions and continuous refinement of production systems.
Collaborative Workflow Hub
Agenta breaks down silos by providing tools for every team member. Domain experts can safely edit and test prompts through a dedicated UI without writing code. Product managers can run evaluations and compare results visually. This seamless collaboration between technical and non-technical roles, supported by full parity between the UI and API, ensures everyone contributes to the iterative cycle of improvement, aligning the entire team on a single, reliable development process.
Fallom
Real-Time Observability
Fallom provides real-time observability for AI agents, allowing teams to track tool calls, analyze timing, and debug with confidence. This feature transforms the debugging process, making it straightforward and efficient, ensuring that every aspect of LLM interactions is monitored effectively.
Cost Attribution
The platform offers detailed cost attribution capabilities, enabling users to track spending per model, user, or team. This feature ensures full cost transparency for budgeting and chargeback, empowering teams to make informed financial decisions based on their AI usage.
Compliance Ready
Fallom is built to support regulatory requirements, offering full audit trails that encompass input/output logging, model versioning, and user consent tracking. This feature ensures that enterprises can meet evolving compliance standards like the EU AI Act, SOC 2, and GDPR, safeguarding their operations.
Session Tracking
With Fallom's session tracking capability, users can group traces by session, user, or customer, providing complete context for every interaction. This feature enhances the ability to analyze user behavior and optimize AI performance, ensuring that teams can respond effectively to their users' needs.
Use Cases
Agenta
Streamlining Enterprise Chatbot Development
Teams building customer support or internal knowledge base chatbots use Agenta to manage hundreds of prompt variations for different intents. Product managers and subject matter experts collaborate in the playground to refine responses, while automated evaluations on real user queries ensure each new prompt version improves accuracy and tone before being safely deployed to production, significantly reducing rollout risk.
Building and Tuning Complex AI Agents
For developers creating multi-step AI agents with frameworks like LangChain or LlamaIndex, Agenta is indispensable for debugging. The full-trace evaluation allows engineers to see exactly which step in an agent's reasoning chain failed. They can save problematic traces as tests, iterate on the prompt or logic for that specific step, and validate the fix within a unified platform, dramatically speeding up development cycles.
Managing LLM Application Quality Assurance
QA teams and ML engineers establish a rigorous, continuous testing regime using Agenta. They build a growing dataset of edge cases and failure modes from production traces. Automated evaluation suites run against this dataset with every code or prompt change, providing quantitative evidence of performance impact. This systematic approach replaces sporadic "vibe checks" with data-driven gating for production releases.
Facilitating Cross-Functional AI Innovation
When a new LLM-powered feature is prototyped, Agenta enables safe exploration. Domain experts can experiment with prompt wording to capture nuanced requirements, while developers integrate new models and APIs. The entire team can view evaluation results, annotate outputs, and collectively decide on the best path forward, ensuring the final product is robust and aligns with both technical and business goals.
Fallom
Debugging AI Performance
Fallom is ideal for teams looking to debug AI performance issues efficiently. By providing real-time visibility into every LLM call, teams can quickly identify bottlenecks and make necessary adjustments to improve overall performance.
Cost Management
Organizations leveraging multiple AI models can utilize Fallom to manage costs effectively. By tracking spend per model and user, teams can ensure they stay within budget while optimizing their AI resource allocation.
Regulatory Compliance
For businesses in regulated industries, Fallom is invaluable. It provides complete audit trails and compliance features, allowing organizations to demonstrate adherence to regulations and avoid potential penalties.
Performance Evaluation
Fallom facilitates the evaluation of LLM outputs, enabling teams to run assessments on accuracy, relevance, and hallucination rates. This capability ensures that AI models are continuously improved based on data-driven insights, ultimately enhancing user satisfaction.
Overview
About Agenta
Agenta is the open-source LLMOps platform engineered to transform how AI teams build, evaluate, and deploy reliable large language model applications. It directly addresses the core challenges of unpredictability and disjointed workflows that plague modern AI development. By serving as a single source of truth, Agenta brings developers, product managers, and domain experts together into a unified, collaborative environment. The platform's primary value lies in its integrated suite for prompt management, systematic evaluation, and production observability, enabling a cyclical and iterative development process. This continuous feedback loop allows teams to move away from scattered prompts in Slack and guesswork debugging toward structured, evidence-based iteration. Agenta is built for any team seeking to implement LLMOps best practices, reduce silos, and ship robust AI products with confidence and speed, fostering a culture of continuous improvement at every stage of the LLM application lifecycle.
About Fallom
Fallom is an innovative AI-native observability platform designed specifically for the iterative development and production-scale operation of large language models (LLMs) and AI agent applications. It addresses the challenges faced by engineering and product teams by providing complete, real-time visibility into every LLM call, turning opaque AI workflows into transparent, debuggable, and optimizable systems. With a core philosophy centered on continuous improvement, Fallom fosters a cyclical process of monitoring, debugging, and refining AI performance. It captures the complete context of each interaction—including prompts, outputs, tool calls, token usage, latency, and cost—delivered through intuitive end-to-end tracing. Whether for agile startups or regulated enterprises, Fallom's single OpenTelemetry-native SDK enables teams to instrument their applications in just minutes, fostering collaboration and providing a unified source of truth. The platform's unique value proposition lies in its ability to accelerate debugging, control and attribute costs, ensure compliance with evolving regulations, and ultimately, build more reliable, efficient AI-powered products through data-driven iteration.
Frequently Asked Questions
Agenta FAQ
Is Agenta really open-source?
Yes, Agenta is a fully open-source platform. You can view the source code on GitHub, self-host the platform on your own infrastructure, and contribute to its development. This ensures transparency, avoids vendor lock-in, and allows for customization to fit specific enterprise needs and security requirements.
How does Agenta handle data privacy and security?
As an open-source platform, Agenta can be deployed within your private cloud or on-premise environment, ensuring your prompt data, evaluation results, and production traces never leave your network. This gives you full control over data governance and compliance, which is critical for teams working with sensitive or proprietary information.
Can Agenta integrate with our existing tech stack?
Absolutely. Agenta is designed to be framework-agnostic. It seamlessly integrates with popular LLM frameworks like LangChain and LlamaIndex, and can work with models from any provider, including OpenAI, Anthropic, Azure, and open-source models. It connects via API, fitting into your existing CI/CD and MLOps pipelines.
What is the difference between Agenta and just using a notebook or spreadsheet?
While notebooks and spreadsheets are useful for initial exploration, they become chaotic and unscalable in team settings. Agenta provides version control, a centralized system of record, structured evaluation workflows, and production observability tools that spreadsheets lack. It transforms ad-hoc, individual experimentation into a collaborative, reproducible, and continuous engineering process.
Fallom FAQ
What is Fallom?
Fallom is an AI-native observability platform that provides real-time visibility into LLM and AI agent applications, focusing on monitoring, debugging, and refining AI performance for improved outcomes.
How does Fallom ensure compliance?
Fallom ensures compliance by offering full audit trails, input/output logging, model versioning, and user consent tracking, which help organizations meet regulatory standards and safeguard user data.
Can Fallom integrate with existing systems?
Yes, Fallom features an OpenTelemetry-native SDK that allows for quick integration with existing systems and workflows, making it easy for teams to get started with observability in under five minutes.
What types of organizations can benefit from Fallom?
Organizations of all sizes, from agile startups to large regulated enterprises, can benefit from Fallom's observability features, which enhance transparency, accountability, and performance optimization in AI applications.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed for teams building applications with large language models. It centralizes the development workflow, focusing on prompt management, evaluation, and collaboration to create more reliable AI systems. This category of tools is essential for moving from experimental prototypes to stable, production-ready applications. Teams explore alternatives for various reasons, including specific feature requirements, budget constraints, integration needs with existing tech stacks, or preferences for different deployment models like fully managed services versus self-hosted solutions. The ideal platform must align with a team's technical maturity and operational scale. When evaluating options, consider core capabilities like systematic testing, version control for prompts, and robust observability. The goal is to find a solution that supports a cyclical, iterative development process, enabling continuous refinement and evidence-based improvements to your LLM applications.
Fallom Alternatives
Fallom is an AI-native observability platform tailored for the development and operational management of large language models (LLMs) and AI agent applications. It enables engineering and product teams to gain comprehensive real-time visibility into each LLM interaction, transforming complex AI workflows into transparent and optimizable systems. Users often seek alternatives to Fallom due to factors such as pricing structures, specific feature sets, or unique platform requirements that align better with their organizational needs. When choosing an alternative, it is crucial to consider the platform's ability to provide end-to-end tracing capabilities, maintain compliance with industry standards, and support continuous improvement processes. Look for solutions that prioritize real-time visibility, facilitate debugging, and offer a user-friendly interface to ensure a smooth transition and effective performance management.