Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right product.
Agenta is the open-source LLMOps platform that centralizes prompt management and evaluation for reliable AI apps.
Last updated: March 1, 2026
OpenMark AI continuously benchmarks over 100 LLMs on your actual task to find the best model for cost, speed, and quality.
Last updated: March 26, 2026
Visual Comparison
Agenta
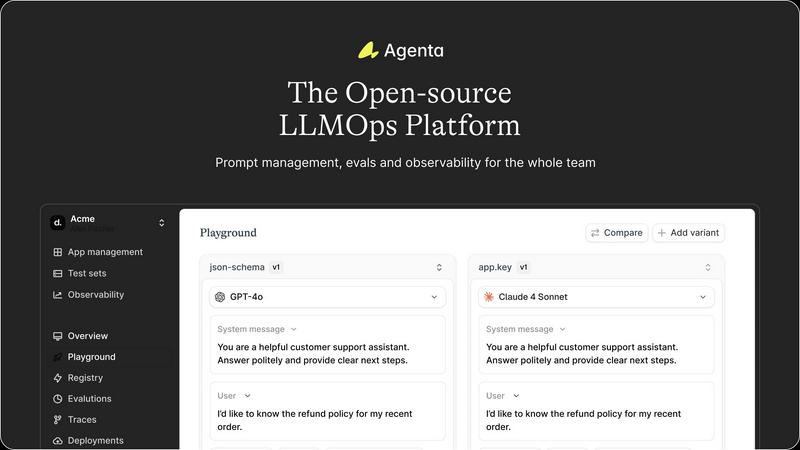
OpenMark AI

Feature Comparison
Agenta
Unified Playground & Experimentation
Agenta provides a centralized playground where teams can experiment with different prompts, parameters, and foundation models from various providers side-by-side in a single interface. This model-agnostic approach prevents vendor lock-in and allows for direct comparison. Every change is automatically versioned, creating a complete history of experiments so teams can track what worked, what didn't, and iterate efficiently based on real data, turning experimentation into a structured process.
Systematic Evaluation Framework
Replace guesswork with evidence using Agenta's comprehensive evaluation system. Teams can create automated test suites using LLM-as-a-judge, custom code, or built-in evaluators. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, to pinpoint failure points. The platform also integrates human evaluation, allowing domain experts to provide feedback directly within the workflow, closing the loop between automated and human judgment.
Production Observability & Debugging
Gain full visibility into your live AI applications with detailed tracing of every LLM request. When issues arise, teams can quickly drill down to find the exact source of errors. Traces can be annotated collaboratively and, with a single click, turned into permanent test cases for future experiments. This capability, combined with live performance monitoring and online evaluations, enables proactive detection of regressions and continuous refinement of production systems.
Collaborative Workflow Hub
Agenta breaks down silos by providing tools for every team member. Domain experts can safely edit and test prompts through a dedicated UI without writing code. Product managers can run evaluations and compare results visually. This seamless collaboration between technical and non-technical roles, supported by full parity between the UI and API, ensures everyone contributes to the iterative cycle of improvement, aligning the entire team on a single, reliable development process.
OpenMark AI
Plain Language Task Description
Describe the exact task you need an AI to perform using simple, natural language—no complex coding or prompt engineering required. The platform allows you to configure everything from simple instructions to advanced, multi-step workflows, making sophisticated benchmarking accessible to developers and product managers alike. This intuitive setup ensures you're testing what you actually intend to build.
Multi-Model Comparison in One Session
Run your defined task against a wide selection of models from various providers simultaneously. This side-by-side testing environment provides immediate, comparable results, allowing you to see how different models stack up against each other on your specific criteria without the hassle of managing multiple API consoles or scripts.
Real Performance & Cost Metrics
Get results based on actual API calls, not cached or theoretical numbers. OpenMark AI measures and displays critical metrics including latency (response time), the actual cost per request from the provider, and a scored assessment of output quality. This gives you a true picture of what to expect in production, focusing on real cost efficiency.
Stability and Variance Analysis
Understand model consistency by seeing how outputs change across repeat runs of the same task. The platform highlights variance, showing you whether a model is reliably good or just occasionally lucky. This focus on stability is crucial for building trustworthy, predictable AI features that perform the same way every time for your users.
Use Cases
Agenta
Streamlining Enterprise Chatbot Development
Teams building customer support or internal knowledge base chatbots use Agenta to manage hundreds of prompt variations for different intents. Product managers and subject matter experts collaborate in the playground to refine responses, while automated evaluations on real user queries ensure each new prompt version improves accuracy and tone before being safely deployed to production, significantly reducing rollout risk.
Building and Tuning Complex AI Agents
For developers creating multi-step AI agents with frameworks like LangChain or LlamaIndex, Agenta is indispensable for debugging. The full-trace evaluation allows engineers to see exactly which step in an agent's reasoning chain failed. They can save problematic traces as tests, iterate on the prompt or logic for that specific step, and validate the fix within a unified platform, dramatically speeding up development cycles.
Managing LLM Application Quality Assurance
QA teams and ML engineers establish a rigorous, continuous testing regime using Agenta. They build a growing dataset of edge cases and failure modes from production traces. Automated evaluation suites run against this dataset with every code or prompt change, providing quantitative evidence of performance impact. This systematic approach replaces sporadic "vibe checks" with data-driven gating for production releases.
Facilitating Cross-Functional AI Innovation
When a new LLM-powered feature is prototyped, Agenta enables safe exploration. Domain experts can experiment with prompt wording to capture nuanced requirements, while developers integrate new models and APIs. The entire team can view evaluation results, annotate outputs, and collectively decide on the best path forward, ensuring the final product is robust and aligns with both technical and business goals.
OpenMark AI
Validating Model Choice for a New Feature
Before committing a model to a new AI-powered feature, use OpenMark AI to test candidate models on a prototype of your exact task. Compare their quality, speed, and cost on real prompts to make a data-driven selection that balances performance with budget, ensuring a strong foundation for your product launch.
Cost Optimization for Existing Workflows
If you're already using an LLM in production, benchmark alternative models to find potential savings. You might discover a less expensive model that delivers comparable quality for your specific use case, or a slightly more expensive one that drastically improves output, allowing for continuous refinement of your operational efficiency.
Ensuring Output Consistency for Critical Tasks
For applications where reliability is non-negotiable—such as data extraction, classification, or automated customer responses—test models across multiple runs to audit their stability. Identify and avoid models with high variance, selecting one that produces consistent, high-quality outputs every time to maintain user trust.
Prototyping and Research for AI Agents
When designing complex systems like AI agents or RAG (Retrieval-Augmented Generation) pipelines, test different LLMs for sub-tasks like routing, summarization, or reasoning. Quickly iterate on your design by benchmarking how various models handle these components, accelerating your research and development cycle with empirical data.
Overview
About Agenta
Agenta is the open-source LLMOps platform engineered to transform how AI teams build, evaluate, and deploy reliable large language model applications. It directly addresses the core challenges of unpredictability and disjointed workflows that plague modern AI development. By serving as a single source of truth, Agenta brings developers, product managers, and domain experts together into a unified, collaborative environment. The platform's primary value lies in its integrated suite for prompt management, systematic evaluation, and production observability, enabling a cyclical and iterative development process. This continuous feedback loop allows teams to move away from scattered prompts in Slack and guesswork debugging toward structured, evidence-based iteration. Agenta is built for any team seeking to implement LLMOps best practices, reduce silos, and ship robust AI products with confidence and speed, fostering a culture of continuous improvement at every stage of the LLM application lifecycle.
About OpenMark AI
OpenMark AI is a powerful web application designed to end the guesswork in selecting large language models (LLMs) for production applications. It provides a comprehensive, task-level benchmarking platform where developers and product teams can describe their specific use case in plain language and run the same prompts against a vast catalog of over 100 models in a single, unified session. The core value proposition is delivering actionable, real-world data for pre-deployment decisions. Instead of relying on marketing claims or single, lucky outputs, OpenMark AI shows you performance variance, scored quality, real API latency, and actual cost per request across repeat runs. This cyclical, iterative approach to testing ensures you can continuously improve your model selection based on hard evidence, not hunches. Built for efficiency, it uses a hosted credit system, eliminating the need to manage and configure separate API keys for every provider like OpenAI, Anthropic, or Google. The platform is designed for those who prioritize cost efficiency—finding the optimal balance of quality relative to price—and need confidence that a model will deliver consistent, stable results every time it's called in a live feature.
Frequently Asked Questions
Agenta FAQ
Is Agenta really open-source?
Yes, Agenta is a fully open-source platform. You can view the source code on GitHub, self-host the platform on your own infrastructure, and contribute to its development. This ensures transparency, avoids vendor lock-in, and allows for customization to fit specific enterprise needs and security requirements.
How does Agenta handle data privacy and security?
As an open-source platform, Agenta can be deployed within your private cloud or on-premise environment, ensuring your prompt data, evaluation results, and production traces never leave your network. This gives you full control over data governance and compliance, which is critical for teams working with sensitive or proprietary information.
Can Agenta integrate with our existing tech stack?
Absolutely. Agenta is designed to be framework-agnostic. It seamlessly integrates with popular LLM frameworks like LangChain and LlamaIndex, and can work with models from any provider, including OpenAI, Anthropic, Azure, and open-source models. It connects via API, fitting into your existing CI/CD and MLOps pipelines.
What is the difference between Agenta and just using a notebook or spreadsheet?
While notebooks and spreadsheets are useful for initial exploration, they become chaotic and unscalable in team settings. Agenta provides version control, a centralized system of record, structured evaluation workflows, and production observability tools that spreadsheets lack. It transforms ad-hoc, individual experimentation into a collaborative, reproducible, and continuous engineering process.
OpenMark AI FAQ
How does OpenMark AI calculate costs?
Costs are calculated based on the actual pricing from each model provider (like OpenAI, Anthropic, etc.) for the tokens consumed by your prompts and the generated completions during the benchmark. OpenMark AI uses real API calls and passes the precise, per-request cost to you, so you see the true expense, not an estimate.
Do I need my own API keys to use OpenMark AI?
No, you do not need to provide or configure any external API keys. OpenMark AI operates on a credit-based system. You purchase credits through the platform, and it manages all the API calls to the various model providers on your behalf, simplifying setup and comparison.
What kind of tasks can I benchmark?
You can benchmark virtually any text-based task, including but not limited to classification, translation, data extraction, question answering, content generation, summarization, code writing, and simulating complex workflows like those used in AI agents or RAG systems. Describe your task in the editor to get started.
How does the platform measure output quality?
Quality is scored through a combination of automated evaluation metrics tailored to your task type and, where applicable, can incorporate your own defined criteria for success. The system analyzes factors like correctness, completeness, and adherence to instruction across all model outputs to provide a comparative quality score.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed for teams building applications with large language models. It centralizes the development workflow, focusing on prompt management, evaluation, and collaboration to create more reliable AI systems. This category of tools is essential for moving from experimental prototypes to stable, production-ready applications. Teams explore alternatives for various reasons, including specific feature requirements, budget constraints, integration needs with existing tech stacks, or preferences for different deployment models like fully managed services versus self-hosted solutions. The ideal platform must align with a team's technical maturity and operational scale. When evaluating options, consider core capabilities like systematic testing, version control for prompts, and robust observability. The goal is to find a solution that supports a cyclical, iterative development process, enabling continuous refinement and evidence-based improvements to your LLM applications.
OpenMark AI Alternatives
OpenMark AI is a developer tool for task-level benchmarking of large language models. It allows teams to test many models simultaneously on their specific use case, comparing real-world performance metrics like cost, latency, and output consistency before committing to an integration. Users may explore alternatives for various reasons, such as budget constraints, a need for different feature sets like automated testing pipelines, or a preference for self-hosted solutions that run on internal infrastructure. The specific requirements of a project often dictate the search. When evaluating other options, consider the scope of supported models, the authenticity of performance data, and the overall workflow. The goal is to find a solution that provides actionable, reliable insights for your pre-deployment validation, ensuring the chosen model balances quality, cost, and stability effectively for your application.