Friendli Engine
About Friendli Engine
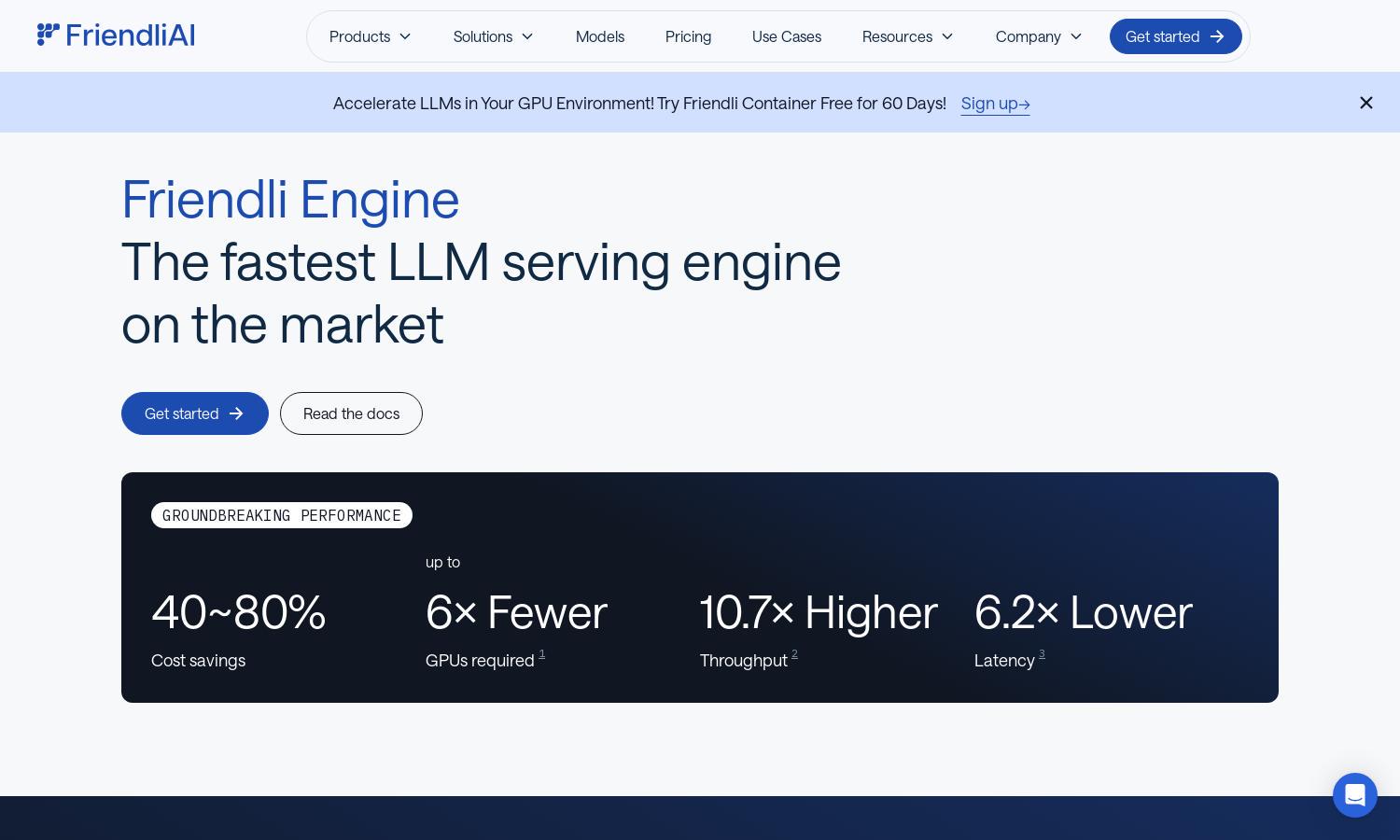
Friendli Engine streamlines generative AI model deployment, targeting developers and AI practitioners. With its unique iteration batching technology, it optimizes LLM inference, significantly enhancing throughput and reducing latency. This way, Friendli Engine addresses the critical challenge of cost-effectiveness and efficiency in AI implementations.
Friendli Engine offers competitive pricing plans, making advanced LLM capabilities accessible. Each tier ensures value for users, with special discounts for long-term subscriptions. Upgrading provides access to enhanced features, guaranteeing superior performance that improves the generative AI experience, particularly for high-demand applications.
Friendli Engine features a clean, intuitive user interface designed for seamless navigation. The layout prioritizes user experience, integrating one-click deployment options and clear access to resources. Unique features like real-time performance tracking enhance usability, making complex generative AI tasks manageable and efficient for all users.
How Friendli Engine works
To get started with Friendli Engine, users begin by signing up and creating an account. Through an intuitive dashboard, they can upload their generative AI models effortlessly. Users then utilize dedicated endpoints or containers to serve LLMs, benefiting from accelerated performance with innovative technologies. Clear guides and support ensure users can efficiently navigate and leverage all functionalities of Friendli Engine.
Key Features for Friendli Engine
Iteration Batching Technology
Friendli Engine features unique iteration batching technology, revolutionizing how LLMs handle concurrent requests. This innovative approach achieves unprecedented throughput, significantly enhancing inference speed while maintaining low latency. Users gain efficiency, ensuring optimal performance for demanding AI applications, solidifying Friendli Engine as an industry leader.
Multi-LoRA Support
Friendli Engine supports multiple LoRA models simultaneously on fewer GPUs, making AI customization more accessible. This capability allows developers to optimize their generative AI solutions, achieving high efficiency without extensive hardware requirements, and alleviating resource constraints typically faced in LLM deployments.
Friendli TCache
The Friendli TCache feature intelligently stores frequently used computational results, optimizing workload on GPUs. By leveraging cached results, Friendli Engine significantly reduces inference times, enhancing user experience and ensuring that LLMs operate at peak efficiency while conserving resources needed for operations.
You may also like: